
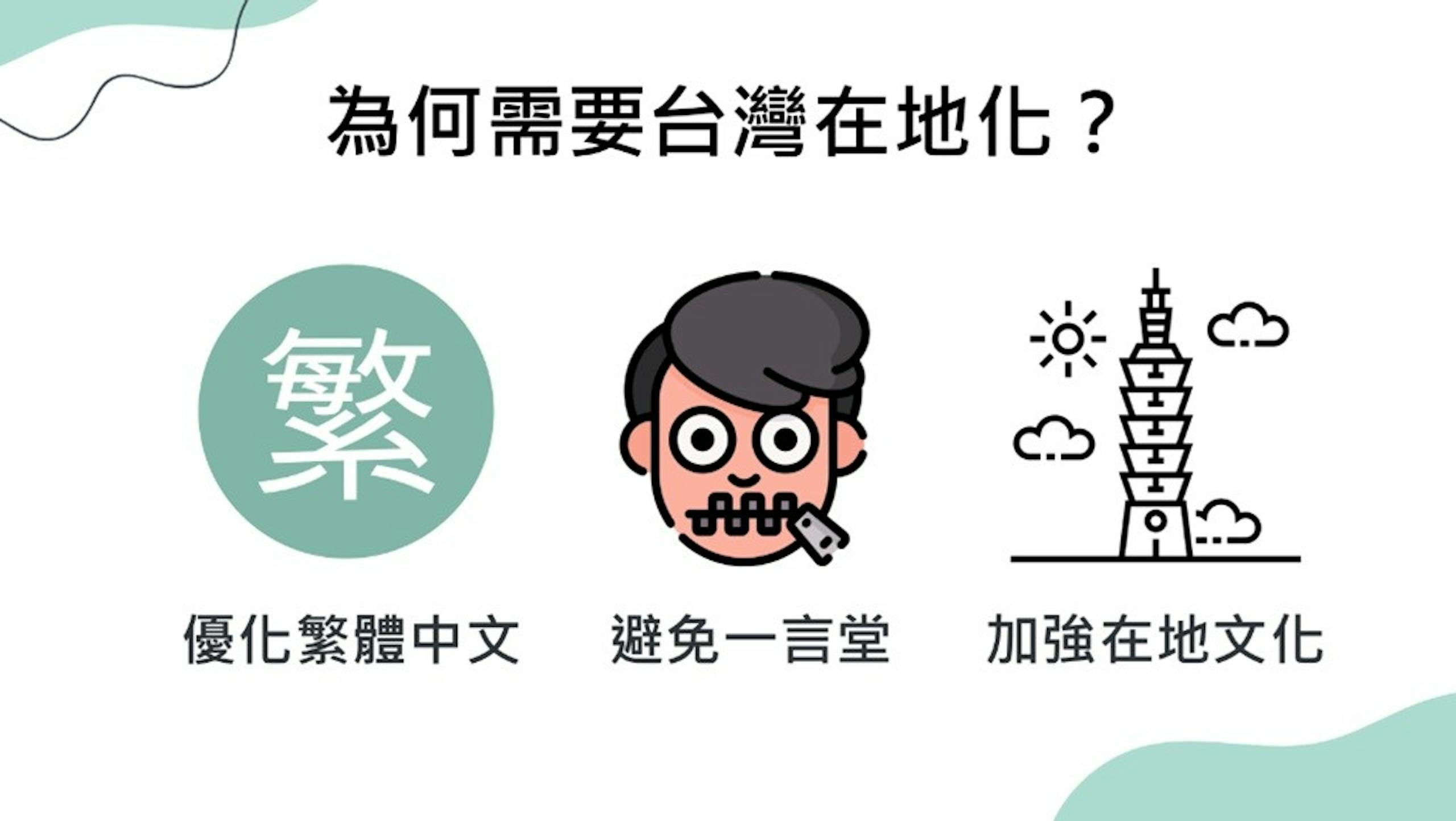
大型語言模型LLM是當前生成式AI技術的核心,然而由於語言的複雜性,主流的知名大型語言模型不見得能理解使用相同文字的差異化語言,如同樣以繁體中文為基礎的台灣繁體中文與香港繁體中文就是一個例子,更不用說許多的中文語系是建立在訓練樣本最高的簡體中文語系,故現在許多國家都興起訓練在地化大型語言模型的計畫;由長春集團、和碩聯合科技、長庚醫院、欣興電子、科技報橘聯合發起,與台大資工系、台大資管系及律果科技合作,並由NVIDIA支持進行訓練的「繁體中文專家模型開源專案 TAiwan Mixture of Experts( Project TAME )」在2024年7月1日上線,並將以開源模型形式廣邀產業加入,共創台灣產業專用AI應用生態系。
Project TAME已在Github開放企業免費下載:Project TAME,同時提供聊天頁面:TWLLM,亞太智能機器則率先整合Project TAME提供機器人測試頁:APMIC
▲在地化的大型語言模型有助提供因地制宜的內容
Project TAME強調不僅具備台灣在地化語言的理解能力,同時還攜手產業提供資料,是目前首創具備產業專業知識的開源模型,有助台灣產業快速且使用較低成本導入生成式AI落地應用;計畫指稱若企業從無到有訓練1B參數模型,需要耗費3.8億新台幣與花費576小時訓練時間,且1B參數的應用也相當侷限,但若透過Project TAME的70B參數模型作為訓練基礎,僅需1,600萬成本、以企業資料訓練模型一次迭代僅需3.5小時。
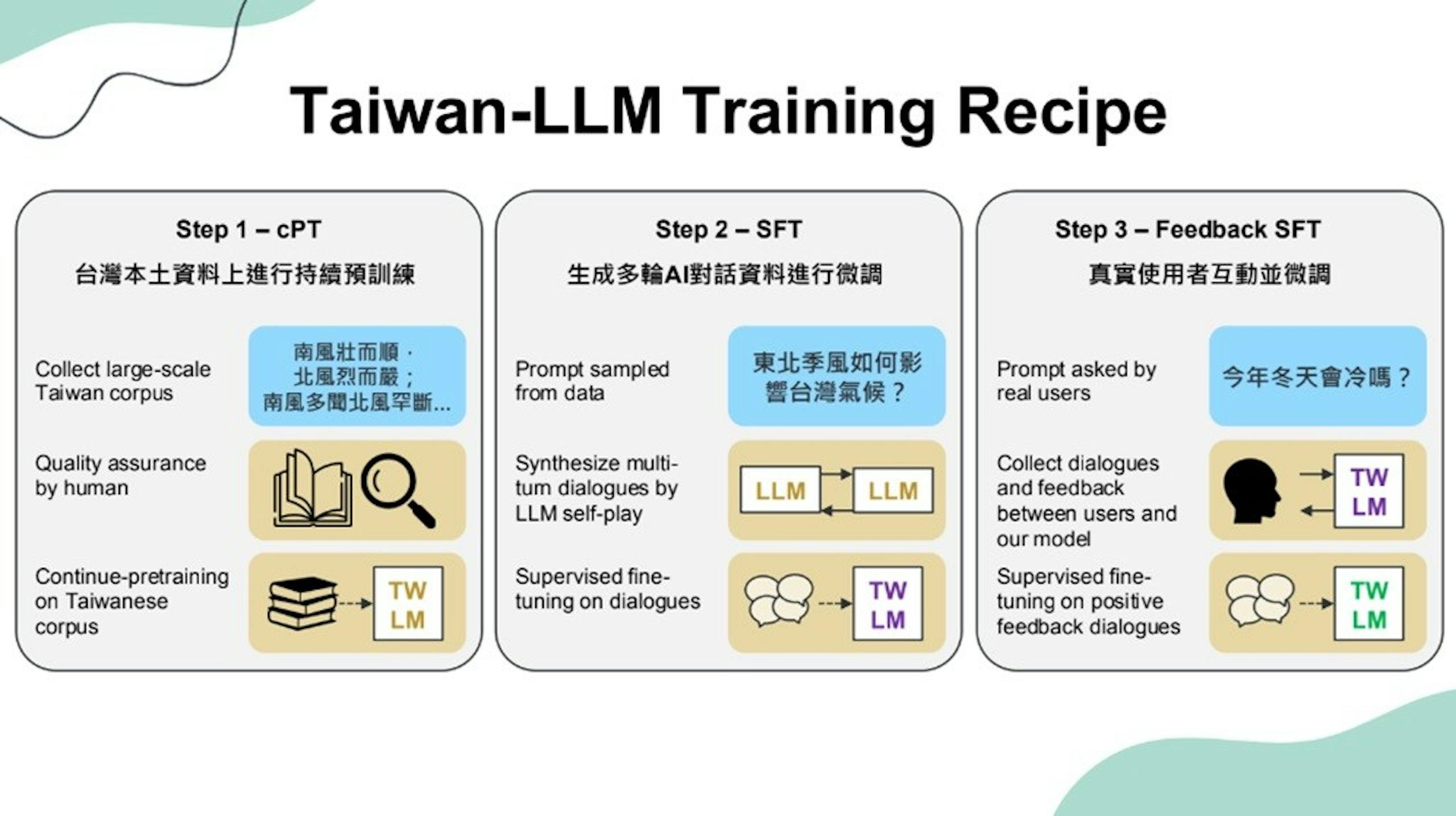
▲透過持續預訓練、微調與互動後微調方式使模型更貼近在地語言使用習慣
Project TAME繁中專家模型開源計畫由台大資工系副教授陳縕儂、實驗室同仁與參與專案的企業夥伴共同合作,並取得NVIDIA開發者計畫支持;Project TAME透過5千億個詞元(Token)完成大型語言模型,除了在地語言以外,相較一般民生娛樂的大型語言模型,Project TAME還具備長春集團、和碩聯合科技、欣興電子、長庚醫院、科技報橘、律果科技等,提供包括石化工業、電子製造、醫療服務、內容服務、法律等各產業領域的在地化專業資料進行訓練。
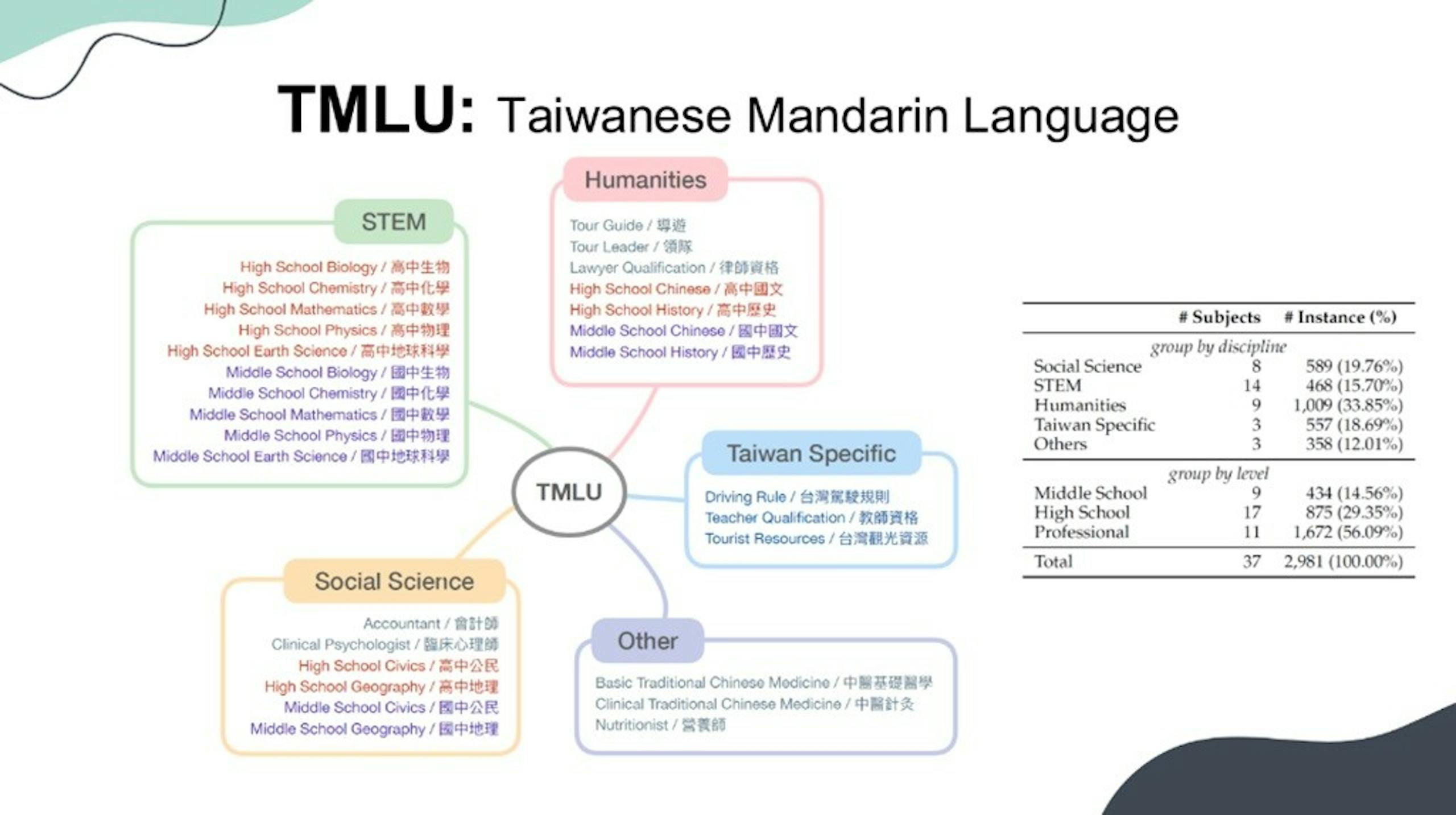
▲Project TAME是首個具備專業領域知識的開源大型語言模型
在計畫啟動僅數個月內,Project TAME已取得初步成果,除了多項繁中相關指標顯著領先以外,包括台灣的大學學測、律師/中醫考試、導遊證照、駕照、台灣在地化測驗也獲得出色的成果,以在地化的39項綜合評測、近3,000個題目進行測試,正確率較第二名的Claude-Opus模型高了6.8%,比GPT-4o更高出9.3%,成功展現在地化語言模型的優勢。

▲本身的模型是建構在70B參數上
幾家參與Project TAME的企業也紛紛分享參與計畫的緣由;長春集團(大連)董事長林顯東指出,他觀察到中國石化業正積極擴張,台灣花近30年才實現近100萬噸的產能,中國僅在兩三年間即達到兩倍的200萬噸,故長春集團希冀透過創新的方式、也就是AI進行預測分析,取得獲利、產品競爭相關的風險,並建立涵蓋企業五大機制的「產銷人發財」的AI戰情分析室。
和碩聯合科技則在設計至系統化生產製造服務積極嘗試AI的可能性與發展AI智造,希望透過參與Project TAME與各產業領域專家資料、學界大型語言模型的專業,加速產業生成式AI應用實踐AI落地。
長庚醫院則表示希望透過AI輔助醫療與照護改善環境,林口常跟醫院院長陳建宗舉例,透過AI繁中大模型導入第一線,使醫師在病歷收尋資料即可彈出具整合所有資料與符合醫師個人作業習慣的患者資訊,使醫師在資料取得事半功倍。
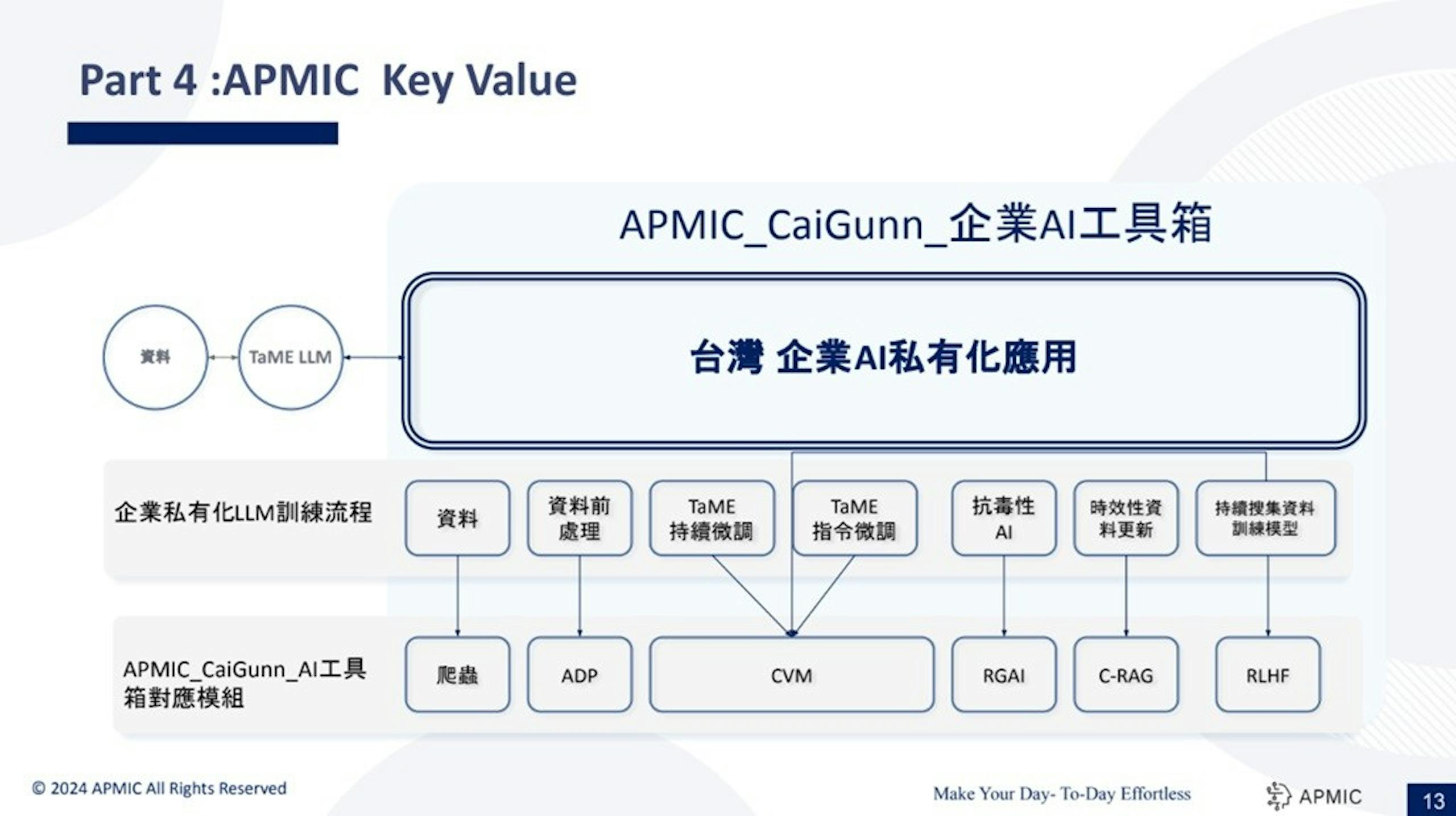
▲企業可藉Project TAME預訓練的成果進行客製化訓練
欣興電子投入Project TAME不僅參與建立公開的繁體中文專家模型,也將其透過公司內部資料庫進行企業客製化應用,將Project TAME轉化為公司內部用的專屬模型,提供公司同仁透過自然語言進行專業知識問答取得符合公司內部作法的答案,藉此提升工作效率。
科技報橘則是受到大型語言模型在內容創作、研究分析情報與個人化的進展,當前已經使用未經繁中最佳化的大型語言模型推出測試性的內容,並呈現在官網的AI人機協作專區,不過在近一年的結果顯示,需有更為在地化的大型語言模型才能提供更適合受眾的在地化內容呈現方式。
專注於法律新創的律果科技則表示法律內容有強烈的在地化需求,因此希望藉由協助Project TAME加入台灣法律語料,而在合作後,台大資工系將Project TAME與各大語言模型進行台灣律師考試項目的測試,Project TAME皆超過其它模型。



















