
歷經微軟在2024年5月宣布的Copilot+ PC計畫,並將其包裝成Windows陣營的進階AI PC,一夕之間整合於CPU的NPU的AI TOPS似乎成為衡量AI PC的戰力單位,套電影「賭神」的經典台詞:任何CPU只要有40 TOPS以上的NPU都可以稱為Copilot+ PC,不過一套性能強大的AI PC真的只要NPU夠強就行嗎?關於這點AI關鍵硬體龍頭NVIDIA肯定不會苟同,故在最新的「解碼AI」系列官方部落格專文,特別針對AI運算單位的TOPS、Token還有Batch Size與AI之間的關係進行解釋。
AI性能基礎計算單位:TOPS
如同遊戲使用FPS作為評量性能的單位一樣,在評估AI性能的基準使用的是TOPS/每秒兆次運算,當然TOPS數字越高也表示執行AI的性能越強大;NVIDIA指出以微軟Copilot+ PC應用當中的裝置端輕度聊天機器人應用,40 TOPS的運算性能已經算是充裕;然而當AI任務以產生更複雜內容與圖像的生成式AI任務時,40 TOPS就僅是杯水車薪;NVIDIA以當前消費級最頂級的顯示卡GeForce RTX 4090為例,GeForce RTX 4090的算力達到1,300TOPS,足以在裝置端處理AI輔助數位內容、遊戲內的AI超解析與畫格生成,自文字或視訊產生影像,以及查詢本機端大型語言模型。
反應大型語言模型運算表現的Token
TOPS是用於廣泛反應AI性能的基本計算單位,不過作為目前最熱門的生成式AI大型語言模型LLM還有更具象徵性的衡量單位,稱為Token;Token譯為詞元,是大型語言模型所產生的結果,Token可以代表句子中的一個字,或式標點符號或空格等較小片段,故執行LLM每秒能產生的Token就成了代表系統執行生成式AI的衡量指標。
Batch Size在生成式AI推論至關重要

▲Batch Size決定一次推論可同步處理的輸入數量
Batch Size為批次大小,是一次AI推論過程同步處理的輸入數量,在大型語言模型成為現代諸多AI系統的核心的當下,能夠處理多個輸入的能力(如來自單一應用程式或跨多程式輸入)將為區分大型語言模型差異的重要因素,Batch Size的容量將決定能同步處理輸入內容表現,同時也需要更大的記憶體,越大的模型需要的記憶體也就更多。
相較於Copilot+ PC的應用是使用主機系統記憶體,在執行大型語言模型需與作業系統、底層應用程式共享記憶體,導致即便配有16GB系統記憶體,也不能全部挪用於執行大型語言模型的Batch Size的記憶體;其中消費級的GeForce RTX顯示卡可提供24GB VRAM、用於工作站的專業繪圖RTX GPU則進一步達到最高48GB VRAM,在不與系統底層共用之下能做為更大容量的Batch Size,並甫以還有為大型語言模型最佳化TensorRT-LLM軟體進一步發揮效能。
GPU執行文字轉影像的生成式AI具壓倒性的表現
Stable Diffusion不僅是當前熱門的文字轉圖像生成式AI,也經常作為生成式AI的效能評估,在這類複雜且具混合性的AI應用,GPU具備比CPU、NPU更高的效能,且若將TensorRT擴充項目與Automatic1111介面,還能進一步提高性能,利用RTX GPU使用SDXL Base檢查點根據提式產生影像的速度提高2倍;而另一項熱門Stable Diffusuion使用者介面ComfyUI甫在6月上旬加入TensorRT加速功能,使圖像生成速度提高60%、搭配Stable Video Diffusion與TensorRT可將影像轉式迅速度提高70%。
透過UL Benchmark的UL Procyon AI圖像測試基準以GeForce RTX 4080 SUPER進行測試,相對速度最快的非TensorRT執行的執行速度提高50%,顯見除了GPU本身的算力,若能再啟用TensorRT還可進一步解放性能。且Stability AI新一代文字轉語音模型Stable Diffusion 3也將能活用TensorRT進行加速,不僅能使效能提高50%,搭配TensorRT-Model Optimizer還能再使效能攀升,相較未使用Tensor-RT性能高出70%,且記憶體用量減少50%。
不過在這類文字轉語音任務最大的挑戰是基於原始提是的反覆運算,即是在產生初步結果後追加描述的再次運算,對比搭配M3 Max處理器的MacBook Pro需花費數分鐘才能進行反覆運算,RTX GPU則可在幾秒內完成反覆運算;雖然這一類任務透過雲端服務能夠獲得更出色的成效,然而牽涉到個人隱私或企業使用,於搭載RTX GPU的高效能PC或工作站離線直行,有助確保資料安全與隱私。
公布結果與開源的公開透明
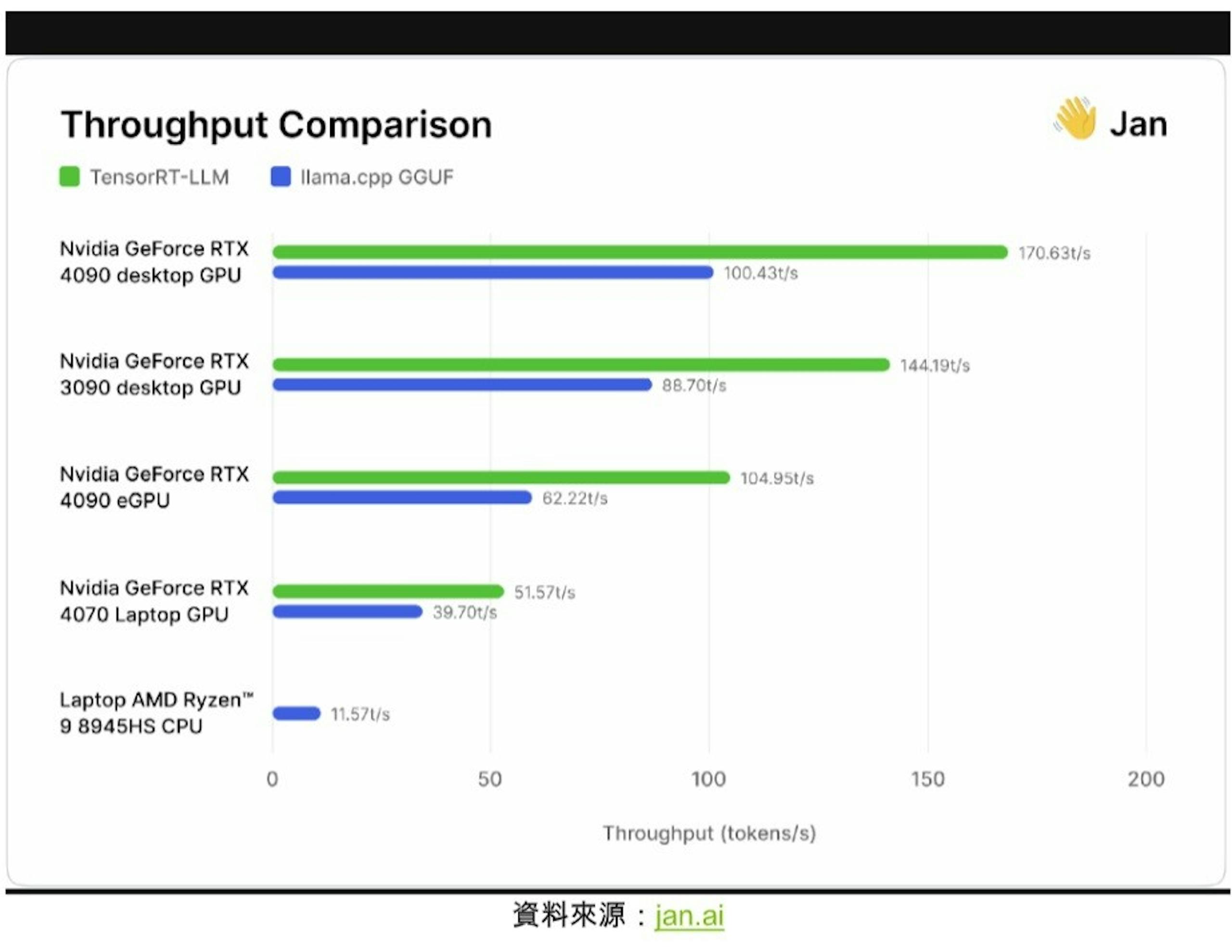
▲jan.ai比較啟用TensorRT前後的結果,發現性能有30%-70%的提升
開源Jan.ai模型的AI研究人員與工作團隊已在日前將TensorRT-LLM納入本機端聊天機器人應用程式,同時也測試這些項目公布結果;研究人員在社群反覆搭配各種GPU與CPU測試,針對開源的Llama.cpp推論引擎測試TensorRT-LLM執行情況,發現在相同硬體導入TensorRT比起Llama.cpp高出30%-70%效能,且在連續處理執行還有更佳的效率,團隊也公布自己的方式邀請其它人員進行生成式AI的效能評估。



















