
NVIDIA在GTC 2024的重頭戲即是宣布以首位美國科學院黑人學者與研究賽局理論與統計學數學家David Harold Blackwell為名的Blackwell GPU架構,以及基於Blackwell架構的NVIDIA B200 Tensor Core GPU;Blackwell採用六項為加速運算而生的革命性技術,首度採用雙晶粒互連構成一個2,080億電晶體的GPU,同時全新的GB200 Superchip(Grace Blackwell超級晶片)更透過NVLink-C2C將2個NVIDIA B200 Tensor Core GPU與1個Grace CPU連接。
基於Blackwell架構的NVIDIA B200 Tensor Core GPU與NVIDIA B200 Tensor Core GPU等產品將陸續於2024年稍晚推出。
雲端服務商亞馬遜AWS、Dell、Google、Meta、微軟、OpenAI、Tesla與xAI都預計採用Blackwell架構GPU提供執行個體。NVIDIA雲端夥伴計劃的公司包括Applied Digital、CoreWeave、Crusoe、IBM Cloud和Lambda也同樣將提供相應的產品,主權AI 雲端也將提供基於Blackwell 的雲端服務和基礎設施,包括Indosat Ooredoo Hutchinson、Nebius、Nexgen Cloud、Oracle EU Sovereign Cloud、Oracle 美國、英國和澳洲政府雲端、Scaleway、Singtel、Northern Data Group 的Taiga Cloud、 Yotta資料服務的 Shakti Cloud 和楊忠禮電力國際。
另外思科、戴爾科技集團、慧與科技、聯想、美超微、永擎電子、華碩、Eviden、鴻海、技嘉科技、英業達、和碩聯合科技、雲達科技、緯創資通、緯穎科技和 雲達國際科技等皆將推出基於Blackwell產品的各式伺服器;Ansys、Cadence和Synopsys等全球領先的工程模擬公司與持續增加的軟體製造商,將使用基於Blackwell的處理器來加速用於設計和模擬電氣、機械和製造系統及零件的軟體
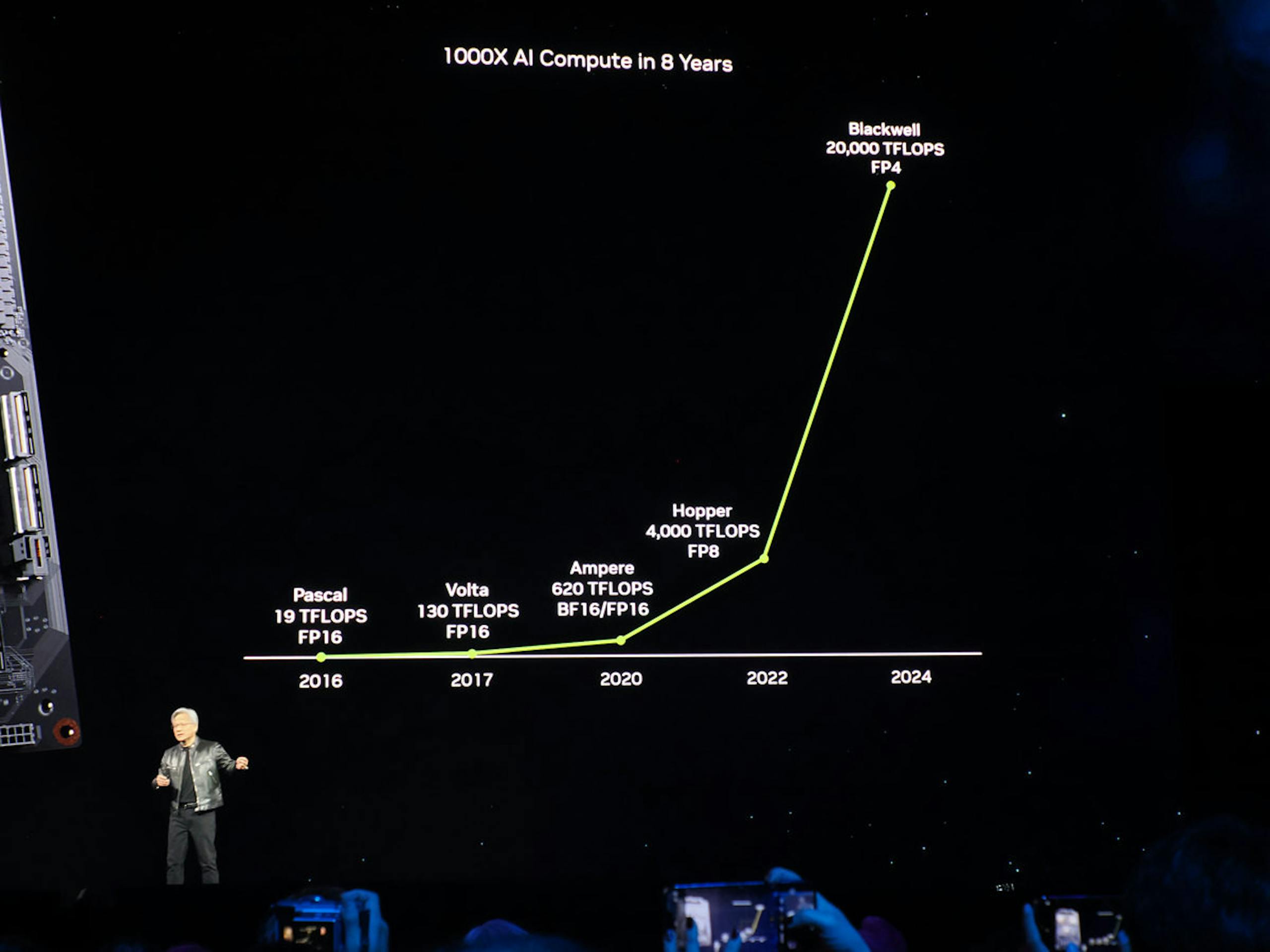
具備六大創新技術、可執行10兆參數的Blackwell

▲Blackwell具六項重大突破特色,包括製程、AI引擎、高速通道、自我診斷、機密運算與解壓縮引擎
Blackwell採用六項重要的的關鍵技術,包括台積電客製化4nm製程的雙晶粒設計,支援FP4的第二代Transformer引擎,達1.8TB/s雙向吞吐量的第5代NVLink,結合AI自我診斷的RSA引擎,具備機密運算功能的安全AI,以及支援最新格式的解壓縮引擎。

▲左為雙晶粒連接的Blackwell GPU晶片,右為H100 GPU晶片
首個雙晶粒設計的NVIDIA GPU:Blackwell架構GPU具備高達2,080億個電晶體,其關鍵是將台積電客製化4nm技術生產的兩倍尺寸GPU裸晶以10TB/s的晶片至晶片通道連接。
第二代Transformer引擎:NVIDIA在Hopper架構首度導入Transformer引擎(Transformer Engine),Blackwell採用第二代Transformer引擎透過微張量擴展(micro-tensor scaling)支援與NVIDIA先進動態範圍管理演算法整合至NIVIDA TensorRT-LLM與NeMo Megatron框架,Blackwell可利用FP4、FP6浮點使AI推論支援更加倍的運算與模型尺寸。
第5代NVLink:NVLink是NVIDIA為解決通用高速連接匯流排傳輸速度不足的高速匯流排技術,Blackwell為了加速多兆參數mixture-of-experts(混合專家)AI模型效能,採用具備雙向1.8TB/s的第5代NVLink,最多可使576個GPU以等同單一GPU般的相互連接,使其能夠無縫執行複雜的大型語言模型。
RSA引擎:為了使Blackwell可實現可靠性、可用性與可服務性,Blackwell整合晶片級功能的專用RSA引擎,可利用AI的預防性維護執行診斷與預測可靠性問題,可使系統正常執行時間最大化,並增強大規模AI佈署彈性,使Blackwell能可靠的在數週至數月不間斷執行、降低營運成本。
安全AI:Blackwell支援新進的機密運算功能,可在不影響效能的前提保護AI模型與客戶資料,同時支援新的本機介面加密協定,對於資料敏感性與隱私權更高的醫療保健與金融服務能至關重要。
解壓縮引擎:Blackwell採用的專用解壓縮引擎支援最新格式,可加速資料庫查詢,藉此提供資料分析與資料科學的最高效能,因應企業在未來幾年將越來越依賴GPU加速處理巨量資料的趨勢。
更龐大的GB200 Superchip與液冷機架規模系統GB200 NVL72

▲GB200 Superchip將1個Grace CPU與2個Blackwell GPU透過NVLink-C2C連接,左方為開發階段的原型、右為量產設計
NVIDIA於H200世代首度推出雙晶粒片連接的Superchip產品,而Blackwell世代則更進一步將1個Grace CPU與2個NVIDIA B200 Tensor Core GPU透過NVLink-C2C晶片對晶片技術以900GB/s的頻寬連接;同時為了提升節點之間連接的性能,NVIDIA也同步公布NVIDIA Quantum-X800 InfiniBand與Spectrum-X800乙太網路平台,可提供基於GB200的系統節點透過800GB/s的高速網路相互連接。

▲GB200 NVL72連接36個GB200晶片,採用液冷散熱

▲GB200 NVL72是新一代DGX SuperPod的基礎

▲以90天進行GPT-MoE-1.8T模型訓練為基準,透過8,000顆H100需耗電15MW

▲同樣90天時間訓練GPT-MoE-1.8T模型,僅需以4MW功率與2,000顆Blackwell GPU即可達到相同的成果
同時,NVIDIA亦宣布由36個GB200 Superchip構成的多節點、液冷機架規模系統NVIDIA GB200 NVL72,NVIDIA GB200 NVL72為新一代DGX SuperPod的基礎,利用第5代NVLink與NVLink Switch技術將72個Blackwell GPU與36個Grace CPU相互連接構成如同單一GPU的平台,可實現1.4exaflops的AI效能與30TB高速記憶體,並配有NVIDIA BlueField-3資料處理單元,於超大規模AI雲端實現雲端網路加速、可組合儲存、零信任安全性與GPU運算彈性。

▲Blackwell與Hopper的基本性能比較
▲除了架構的純性能提升,支援FP4精度也使Blackwell於推論性能大幅提升

▲Blackwell在同樣FP8精度下的推論性能即高於Hopper,若採用FP4精度甚至可提升30倍推論
相較NVIDIA H100 Tensor Core GPU,GB200 NVL72可提供30倍的大型語言模型LLM推論負載,並減少25倍的成本與能源消耗。同時GB200也將透過NVIDA DGX Cloud提供,使企業開發人員可透過雲服務商共同設計的AI平台專門存取建置和部署先進生成式AI 模型所需的基礎設施和軟體,AWS、Google Cloud與Oracle Cloud Infrastructure將在2024年稍後託管基於GB200的新執行個體。

▲左為搭配x86 CPU的HGX B200,其設計可與DGX H100相容、不須重新設計
同時,NVIDIA也公布基於x86 CPU的HGX B200,其架構可沿用針對DGX H100的設計,共可透過NVLink連接8個B200 GPU,並結合NVIDIA Quantum-2 InfiniBand與Spectrum-X乙太網路平台提供400Gb/s的網路速度。



















