
NVIDIA 宣布包括 NVIDIA GH200 、 NVIDIA H100 、 NVIDIA L4 GPU 與 Jetson Orin 等在 2023 年 9 月公布的 MLPerf 推論測試基準獲得出色且領先的表現,其中 NVIDIA GH200 Grace Hopper Superchip 更是首度提交 MLPerf 測試結果,展現透過整合 CPU 與 GPU 在單一超級晶片提供更多記憶體、頻寬以及主動平衡 CPU 與 GPU 電力帶來的效益;此外 NVIDIA 也公布針對大型語言模型的 TensorRT-LLM 軟體,進一步針對 NVIDIA 硬體特性、跨 GPU 與節點運算最佳化,使 NVIDIA H100 在搭配 TensorRT-LLM 後於大型語言模型推論有飛躍的提升。
此次是 NVIDIA 首度遞交 NVIDIA GH200 Grace Hopper Superchip 的測試結果,不過畢竟是首度進行測試,僅以單一晶片進行測試,但已經展現出 NVDIIA GH200 高度整合與具備大量記憶體、優異的效能能耗比的特性;而此輪每個 MLPerf 推論測試提供最高推土量的系統為配備達 8 個 H100 GPU 的 HGX 100 系統;同時 Grace Hopper 與 H100 GPU 也在包括電腦視覺推論、語音識別、醫學成像、推薦系統案例、生成式 AI 應用所需的大型語言模型處於領先地位,並延續 NVIDIA 自 2018 年以來於 MLPerf 基準的持續領先紀錄。

▲ Tensor-LLM 使既有 NVIDIA H100 客戶不需更新硬體也可顯著提升效能,並進一步擴大與前一代 A100 在推論的效能差
此輪的 MLPerf 也針對推薦系統測試進行更新,同時針對大型語言模型推論導入 GPT-J , GPT-J 為具備 60 億個參數的大型語言模型,可做為衡量系統執行新一代為生成式 AI 基礎的大型人工智慧模型的粗略基準。同時 NVIDIA 也展現甫公布的 TensorRT-LLM 開源軟體在 MLPerf 展現的效益,相較 8 月份尚未開發完成的測試結果,客戶能在毋需添加任何硬體成本下,以既有的 H100 GPU 提升一倍以上的推論效能,並進一步發揮多 GPU 與多節點的效益,尤其在 GPT-J 6B 的測試成績甚至可提升達 8 倍。
另外針對基礎設施與推論最佳化的 NVIDIA L4 也展現出色的能耗效能比,僅有 72W 能耗且小型化設計的 NVIDIA L4 可相較功耗 5 倍以上的 CPU 在推論發揮 6 倍效能,同時內建專屬媒體引擎,搭配 CUDA 軟體,能使電腦視覺應用較 CPU 提升達 120 倍;目前 NVIDIA L4 也廣泛獲得採納,自消費者網路服務自藥物研究等產業都可見其身影。此外 NVIDIA 借助全新模型壓縮技術,使 NVIDIA L4 執行 BERT LLM 的效能可提升 4.7 倍。
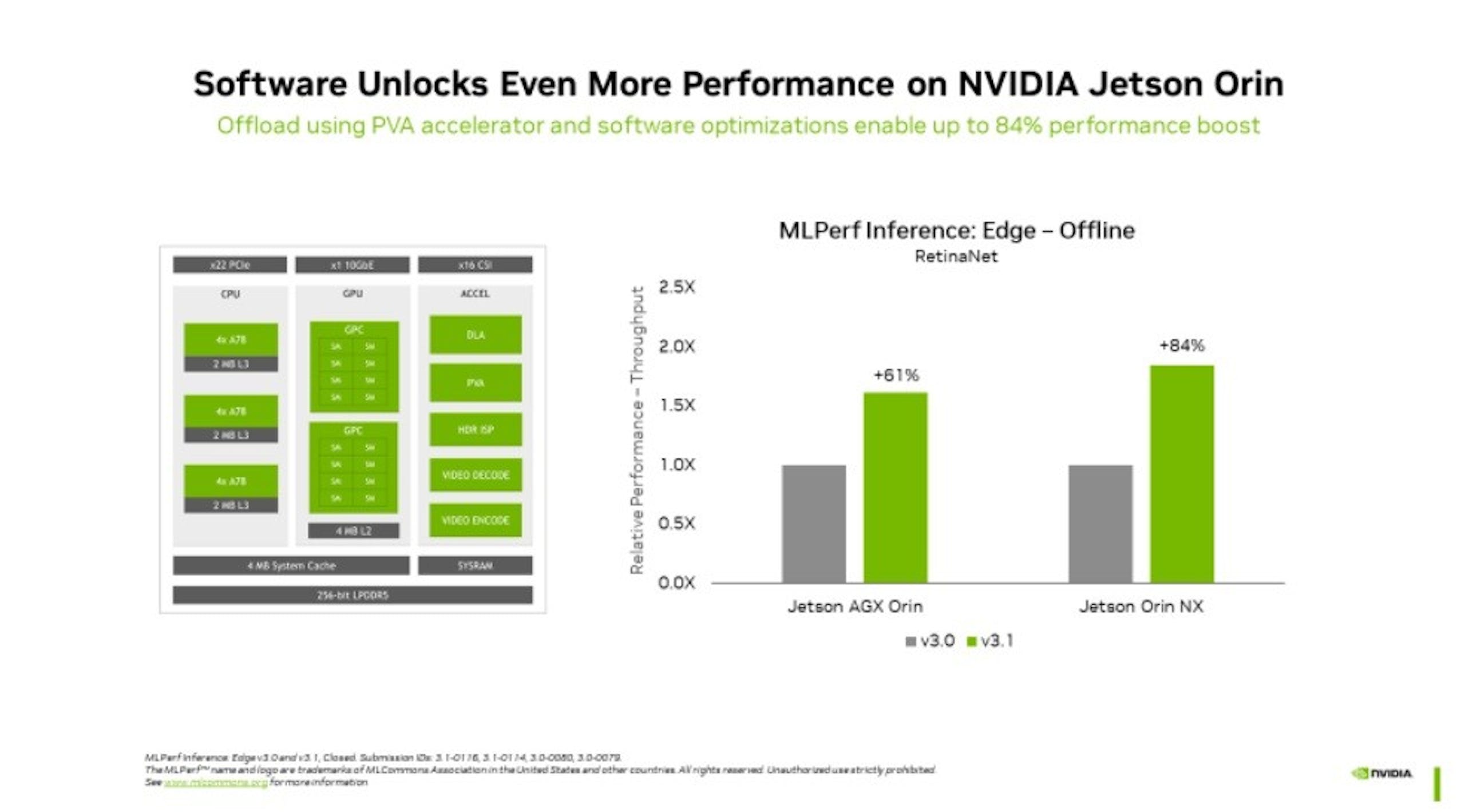
▲ Jetson Orin 在邊際推論設備展現低能耗、高效能的表現
NVIDIA Jetson Orin 平台可說是在尺寸與攻耗受限的邊際設備執行 AI 模型的絕佳選擇, Jetson Orin 不僅具備出色的 CPU 與 NVIDIA Ampere 架構 GPU ,同時還整合深度學習加速器,同時 NVIDIA 持續更新軟體套件之下, NVIDIA Jetson Orin 較前一輪測試在物件偵測效能提升達 84% ,對於邊際人工智慧與機器人的機器視覺應用是相當大的突破。



















