NVIDIA 能在 AI 領域持續引領風騷,不僅只是靠出色的硬體以及在對的時間推出合宜的產品,更重要的是長期在軟體與社群耕耘,並持續與產業夥伴開發各式工具降低進入 AI 領域的門檻; NVIDIA 於 2023 年 9 月宣布將在未來幾週公布開源的 NVIDIA TensorRT-LLM 軟體,強調將使開發者不須深厚的 C++ 或 NVIDIA CUDA 即可嘗試新的大型模型,並提供峰值效能與快速自訂功能。
NVIDIA TensorRT-LLM 已開放早期適用,預計在不久後整合至隸屬 NVIDIA AI Enterprise 的 NVIDA NeMo 框架。TensorRT for Large Language Models Beta Release
NVIDIA TensorRT-LLM 將協助 NVIDIA H100 GPU 在大型語言模型( LLM )推論取得突破增長。 NVIDIA TensorRT-LLM 由 TensorRT 深度學習編譯器構成,包括最佳化調整內核、前處理與後處理步驟及多 GPU 、多節點通訊基元等;同時 NVIDIA TensorRT-LLM 透過 Python API 開源模組提升易用性與擴充性,可作為定義、最佳化與執行新架構,同時可隨大型語言模型發展增強,並輕鬆自動相關內容。
如 MosaicML 在 NVIDIA TensorRT-LLM 的基礎無縫增加所需的特定功能,並輕鬆的整合至推論服務中, 。Databricks 工程部門副總裁 Naveen Rao 指出 NVIDIA TensorRT-LLM 同時提供包括詞元串流處理( streaming of tokens ),動態批次處理( in-flight batchig ), paged-attention 、量化等完整功能,同時效率極為出色。
進一步發揮 H100 與 NVIDIA NVLink 技術的效能
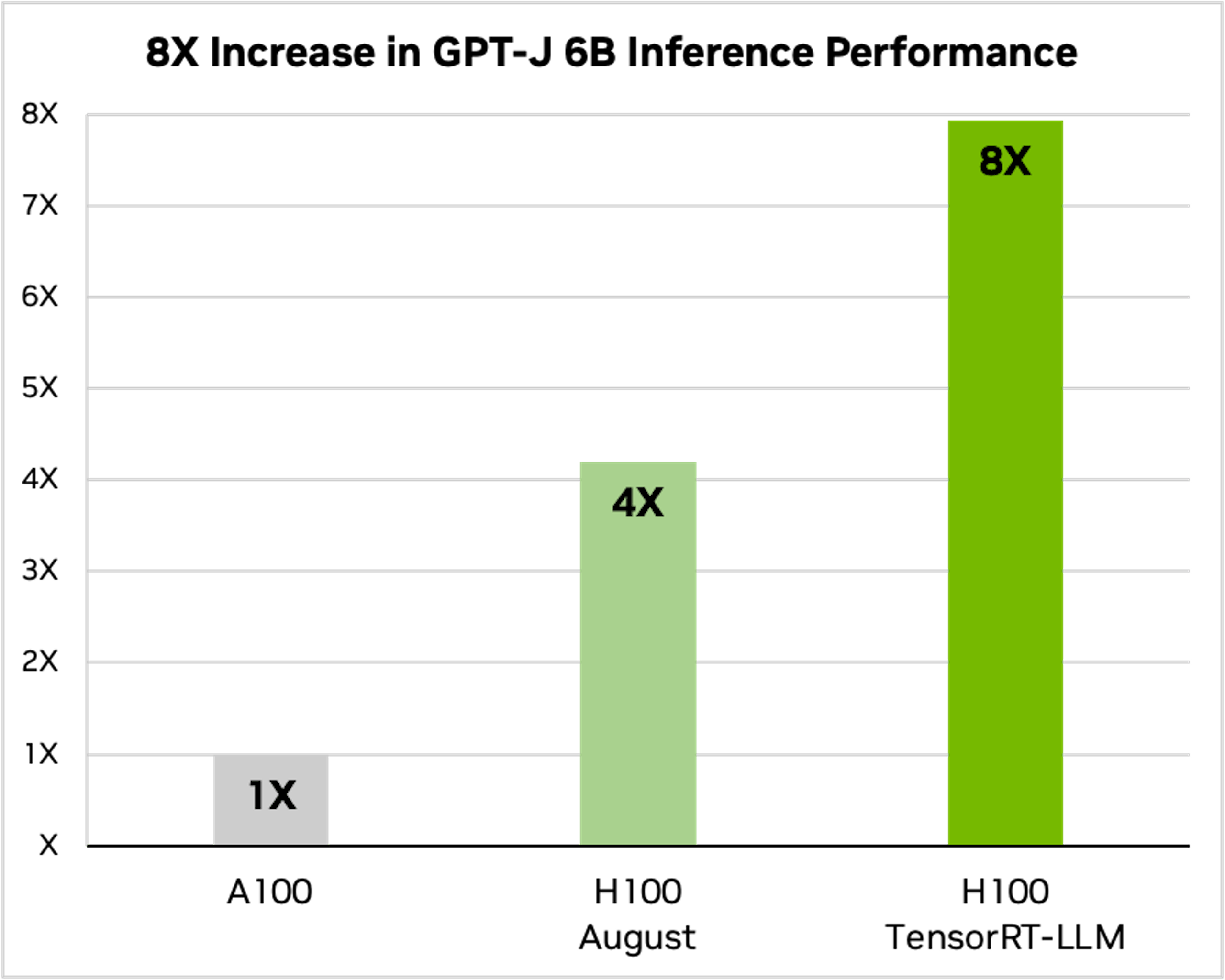
▲在 60 億個參數的 GPT-J 6B 效能可較非導入前翻倍
NVIDIA 也列舉出數據比較使用 NVIDIA TensorRT-LLM 帶來的助益; NVIDIA 以 A100 作為比較基準,再已相同執行條件的 NVIDIA H100 、導入 TensorRT-LLM 的 H100 性能對比,其中以 60 億個參數 GPT-J 6B 進行效能評估, NVIDIA H100 在基礎效能已高出 A100 達 4 倍,導入 TensorRT-LLM 、動態批次處理等技術後,總吞吐量提箱較 A100 提升達 8 倍。
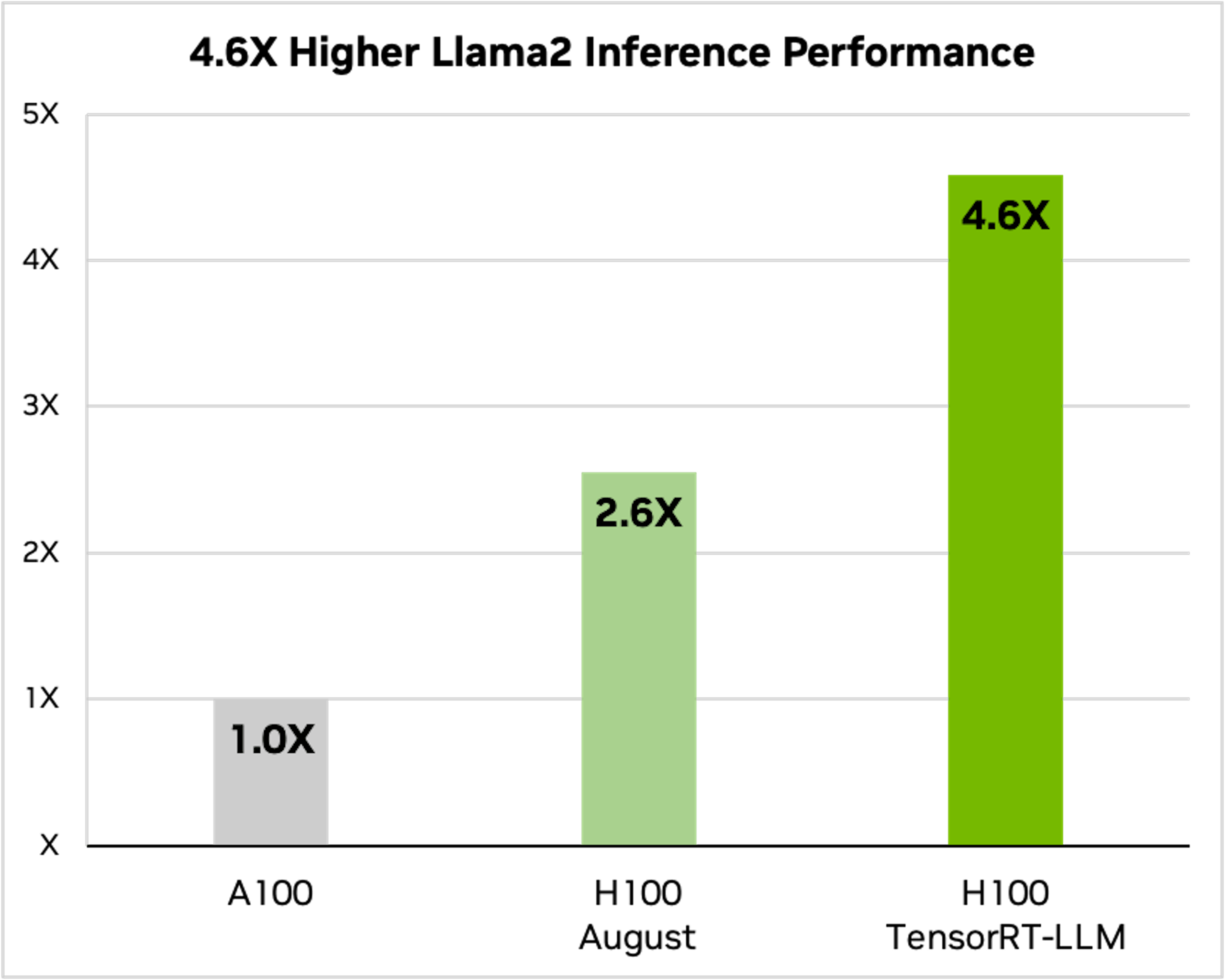
▲在 700 億個參數的 Llama2 也可帶來顯著的提升
透過 Meta 公布、具 700 億個參數的新一代大型語言模型 Llama2 進行比較,在此情境下 H100 基礎性能仍高出 A100 達 2.6 倍,而結合 NVIDIA TensorRT-LLM 的 H100 進一步對比 A100 提升到 4.6 倍。
為新一代大量參數 LLM 與跨 GPU 、節點硬體提供簡單易用的體驗
在這些數據比較的背後,NVIDIA TensorRT-LLM 可說是因應新一代具大量參數的大型語言模型而來,如具備 700 億個參數 Llama2 勢必需要大量的 GPU 協作才能提供即時回應,若在當前的情況,開發者是必須要重寫與手動將 LLM 模型分割成多個片段,才能進行跨多 GPU 的協調執行。
而 NVIDIA TensorRT-LLM 利用一種模型平行化( model parallellism )的 tensor 平行,將個別權重矩陣分割至各個裝置,不再需要開發者干預或出手修改模型,級可活用透過 NVLink 連接的多個 GPU 與多個伺服器平行執行每個模型,使大規模多 GPU 、多節點運算更具效率。
此外,因應不斷推陳出新的模型與模型架構,開發者可利用 TensorRT-LLM 的開源型態的最新 NVIDIA 人工智慧內核,將模型調整至最佳狀態;其內核融合包括尖端的 FlashAttention 和 Masked Multi-Head Attention 技術,用於GPT模型執行的上下文和生成階段,以及許多其他功能等。
且 TensorRT-LLM 還包含當前環境中已廣泛被使用的許多大型模型語言模型的最佳話、可立即執行版本,可借助 TensorRT-LLM Pyton API 操作諸如 Meta Llama 2、OpenAI GPT-2 和 GPT-3、Falcon、Mosaic MPT、BLOOM 等大型語言模型。
因應大型語言模型多元性的動態批次處理
現行的大型語言模型相當多樣化,一個模型可同時處理多種差異性極大的任務,自簡單的一問一答、到文件摘要至生成長篇程式碼,需透過高度動態的方式處理這些工作,而不同任務輸出的大小天差地遠;然而這樣的特性可能會導致難以現行透過服務神經網路的有效批量處理請求並執行這些任務,會導致某些請求較其它請求更先完成,導致服務進度的順序出現錯誤。
為了管理這些動態負載,TensorRT-LLM 包含一種稱為動態批次處理( In-flight batching ) 的最佳化調度技術,可將大型語言模型的整體文字生成過程拆分在模型上執行的多次迭代。 TensorRT-LLM 利用動態批次技術使處理程序不會等到整個批次處理完成才進行下一組請求,而是即可將已完成的住列自批次處理中移除。在其它請求仍被處理的過程就開始執行新的請求。動態批次處理與額外的內核級最佳化技術可進一步提升 GPU 使用率,使 H100 Tensor Core GPU 實際 LLM 請求基準的吞吐量最少提升一倍。
發揮 H100 Transformer Engine 加上 FP8 的效益

▲ H100 支援的 FP8 格式相較 INT8 、 INT4 有更好的準確性
一般含數十億個參數的模型銓重雨啟動項目的大型語言在訓練與表示多使用 16bit 浮點( FP16 或 BF16 ),不過在推論階段大多模型可使用現代量化技術有效表示為較低精度如 Int8 或 Int4 的整數;量化是在不降低準確度的前提降低模型權重雨啟動精度的過程;使用較低精度代表每個參數更小、模型占用 GPU 的記憶體空間也更小;如此一來使得相同硬體條件可對更大型的模型進行推論,並在執行過程減少記憶體運作時間。
借助 TensorRT-LLM , NVIDIA H100 能夠輕鬆將模型權重轉換為新的 FP8 格式,同時自動編譯模型以利用最佳化 FP8 內核,且透過 Hopper 架構的 Transformer Engine ,不需變動任何模型程式碼。
H100 導入的 FP8 資料格式能使開發者量化他們的模型,並在不降低模型精確度的前提大幅減少記憶體消耗,同時相較 INT8 與 INT4 等其它資料格式, FP8 量化能保有更高的準確度,並實現更快的效能表現與最簡單的實現。



















