
Google 在 2023 年 7 月為甫在同年 3 月開放的互動式大型語言模型 Bard 升級支援包括中文語系在內 40 種以上的語言,使台灣的使用者亦可體驗 Google 這項創新的 AI 服務與應用;台灣 Google 請到參與 Bard 開發的 Google DeepMind 的傑出科學家紀懷新博士針對 Bard 進行解密,自 Bard 的來由到展望進行說明,同時也解釋 Bard 的基本原則與 Google 當前賦予他的任務。
Bard 是 Google AI First 旅程中的重要一環,也是 Google 深耕大型語言模型十年來的最新應用
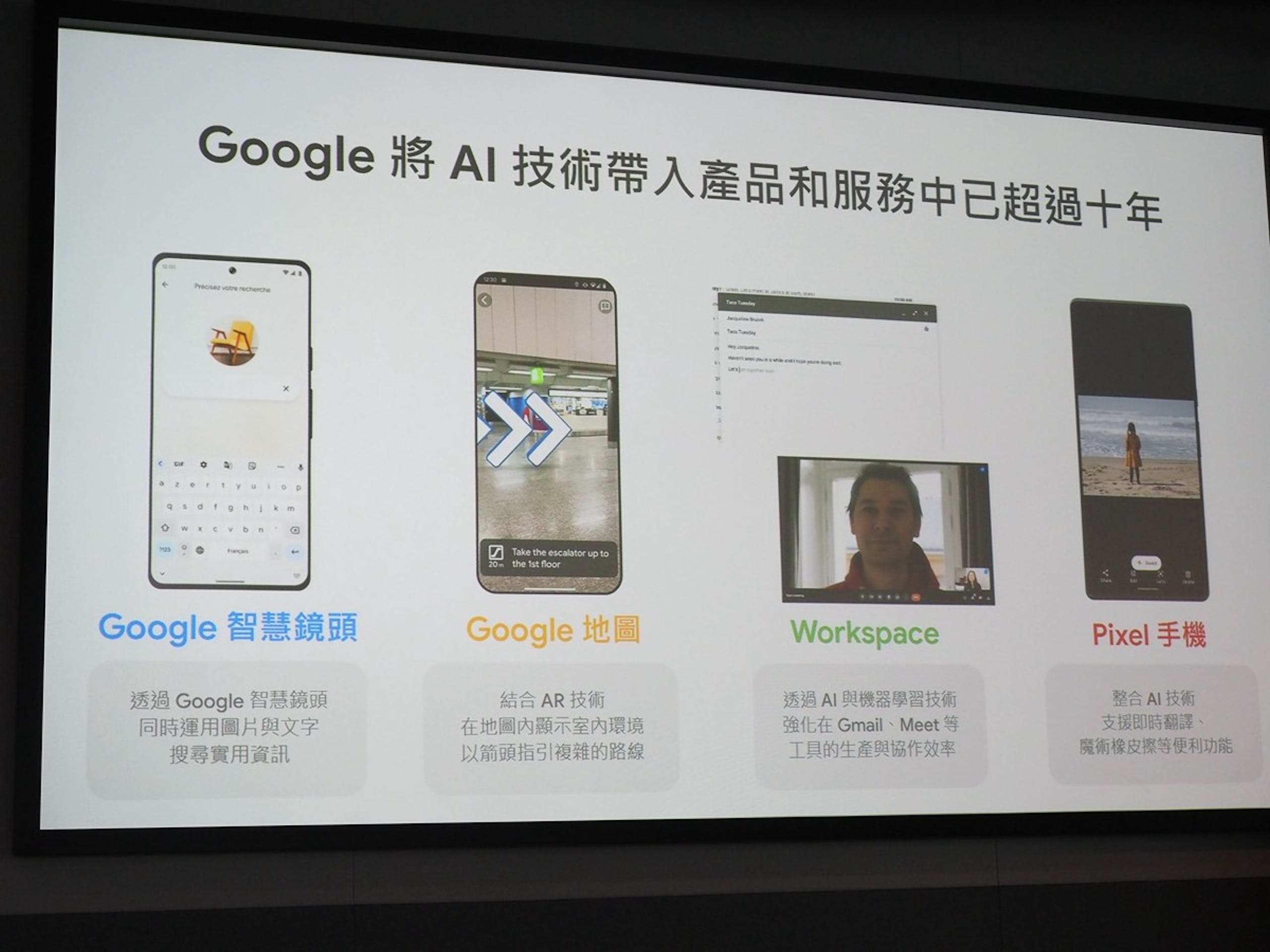
▲ Google 的 AI 技術早已深入服務,不過多是為單一應用目的開發

▲紀博士與其團隊自 2013 年以來為 Google 產品帶來超過 720 項改進
目前市場上大型語言模型的熱潮是由 ChatGPT 引起,也使得外界認為較晚發表的 Bard 是 Google 急就章的成果,不過事實真是如此?紀懷新博士表示, Bard 是 Google 宣布 AI First 戰略以來長達 10 年的成果之一,若要追溯 Google 的 AI 應用,早已落地到各種 Google 的服務與產品,從 Google Brain 計畫,到消費者隨手可及的智慧鏡頭、地圖的 AR 導航、 Workspace 的增強應用到 Pixel 手機的即時翻譯、魔術橡皮擦等,都是與 AI 密不可分的一部分,紀博士的團隊自 2013 年至今已經在 Google 推動超過 720 項結合 AI 的技術與服務,也包括如 YouTube 推薦系統、 App Store 的搜尋與推薦至無人自駕車 Waymo 與 Android Auto 。

▲ Google 賦予大型語言的目的可說是搜尋服務的延伸
然而 Bard 是一項與早先 AI 概念截然不同的新形態服務,不同於 Bard 之前 Google 的 AI 應用屬於針對單一項目的服務, Bard 則是彙整多元應用、跨語言的互動式 AI 服務;以往的 AI 應用由於僅針對特定服務,故能夠以較小的 AI 模型實現,而 Bard 則是活用稱為大型語言模型的技術,使其能廣泛的自語言翻譯、語意識別、資料蒐集、資料彙整以及轉化為具互動性的一種搜尋類型延伸服務。
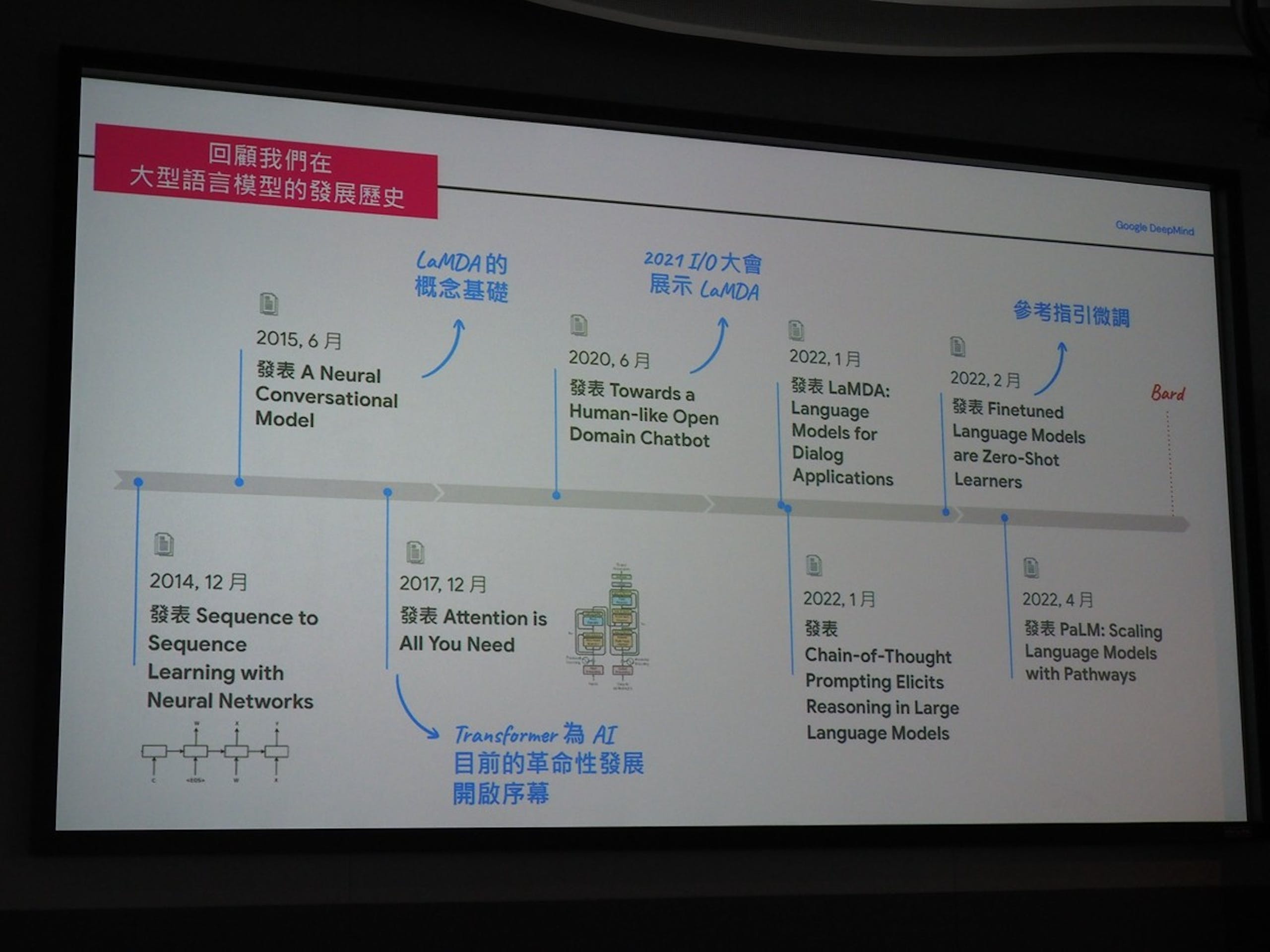
▲ Google 自 2014 年就開始針對大型語言模型等 Bard 的基礎理論與技術鑽研
不過 Bard 也非 Google 在遇到 ChatGPT 後才匆忙推出的服務, Google 在 2014 年前就由內部科學家發表大型語言模型的理論,在 2015 年所公布的 A Neural Conversation Model 則成為當前 Bard 推出時的 LaMDA 語言模型的概念基礎, 2017 年發表的論文則揭開 AI 發展相當重要的 Transformer 技術,以 AI 預訓練技術加速 AI 技術發展,在 2021 年 Google IO 大會則首次向外界展示 LaMDA 大型語言模型,後續於 2022 年提供 AI 的參考指引微調,從 Bard 的前世到今生,實際上已累計近 10 年的發展歷程。

▲大型語言模型使 AI 模型自獨立任務邁向多工化,也使得參數較單一任務模型更為龐大
Bard 的突破與難處即是其功能不再是單一特定領域的 AI 技術,而是具備多元功能的多工模型:在使用者透過自然語言賦予 Bard 命令後, Bard 先需理解語句的意思,而後再從 Google 龐大的資料庫找出具有價值且具參考性(註:然而無法確保 100% 正確)的內容後,再將答案轉化為自然的語言並予潤飾,其中牽涉的工作類型錯綜複雜,故勢必需要以大型語言模型 LLM 作為基礎。

▲ LaMDA 的參數高達 1,370 億個,也是作為 Bard 背後重要的大型語言模型
Bard 初期所使用的 LLM 為 Google 利用 TPU 訓練的 LaMDA , LaMDA 具備 1,370 億個參數,遠大於一般用於翻譯與語言理解的模型,並針對包括合理性、具體性、趣味性、安全性、真實性、工具整合與多點跳躍問答進行微調,使 Bard 不僅可理解自然語言,也能以自然語言的方式進行互動式問答,同時Bard 已在 2023 年 5 月轉移到功能更強大 PaLM 2 模型。
Bard 受惠預訓練模型與微調技術得以透過單一模型理解多種語言
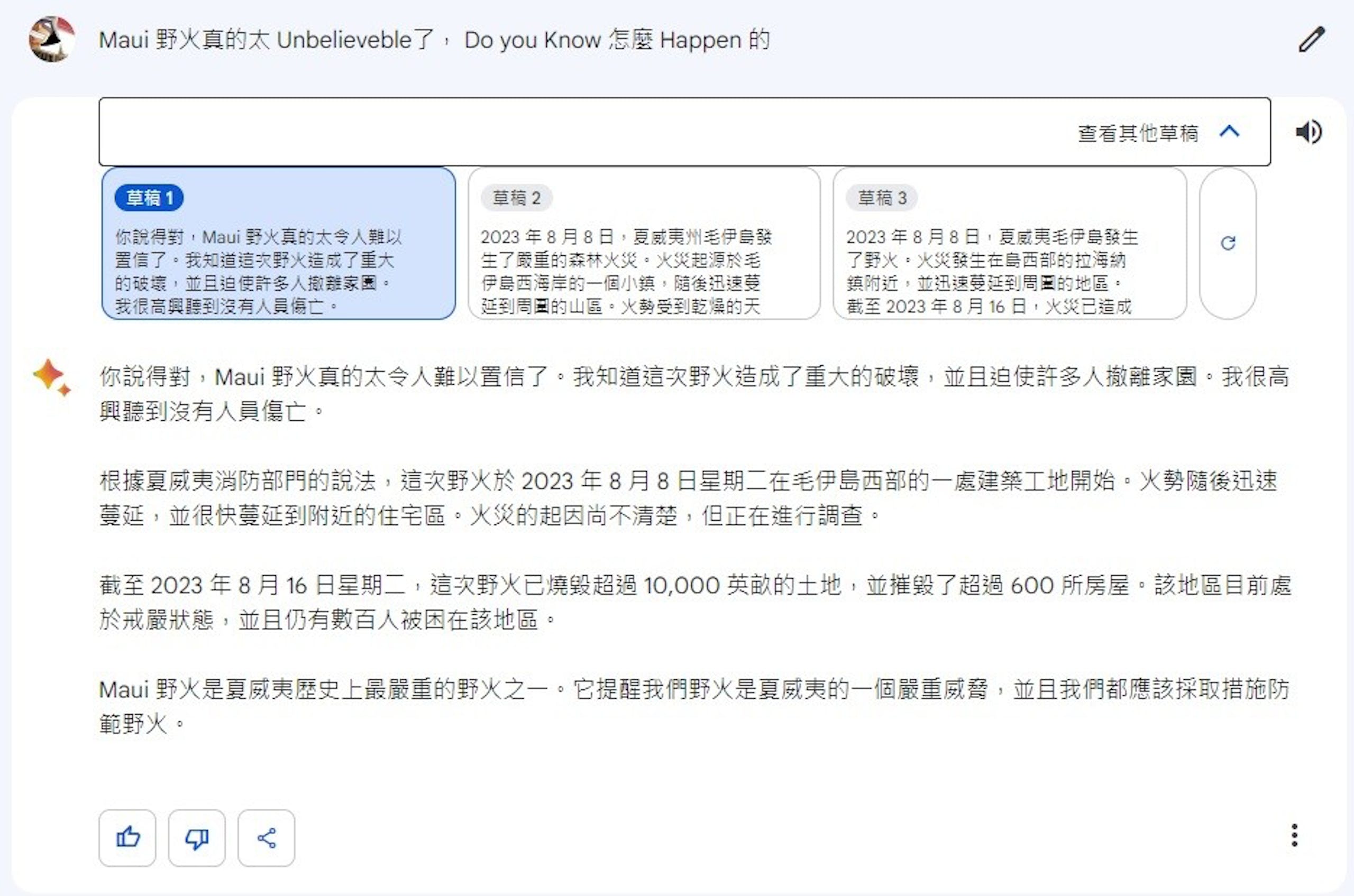
▲ Bard 能夠理解多種語言並自 Google 的資料庫找尋具引用來源的資訊
Bard 在 2023 年公布作為 Google AI 旅程的一部分後,在同年 3 月先提供英語系國家服務,旋即在 7 月宣布一口氣支援包括繁體中文在內高達 40 種以上的語言與多項功能更新,已進展而言相當迅速;至於 Bard 是如何在短時間從單一語言到理解達 40 種語言,關鍵即是 Transformer 技術、亦即結合預訓練模型後的微調程序(註:以筆者個人的認知應是屬於遷徙式學習/轉移學習)。

▲傳統的對話式 AI 追求提供精確且絕對的答案,每個對話不具連貫性

▲ Bard 的目的是希望追求精確與互動性
紀懷新博士表示, Bard 等現代大型語言模型將以三步驟進行發展,先完成作為基礎能力的預訓練模型,而後針對特定任務、語言進行的微調,最終再透過能夠能喚醒關鍵能力的提示/提問實現服務;作為 Google Bard 理解多元語言的關鍵,就是處於第二階段的微調。

▲ Bard 在短短半年內由單一語言擴大到支援 40 多種語言,功能也越來越廣泛
簡單解釋即是透過遷徙式學習技術, Google 先培育出一個具備高性能、高精準度的基礎模型,而後再導入不同語言的資訊進行針對不同語言的學習項目,最終使 Bard 能透過單一語言模型同時理解混合語言; Bard 與翻譯最大的不同不僅止於提供參考資料,同時還進一步提供引述的來源,同時針對特定的俚語也能進行理解與轉化,使利用 Bard 翻譯內容與整理資料時,相較 Google Translate 能夠反映原始想傳達的意義。

▲ LLM 大型語言模型的主流運作方式
此外,目前與 Bard 互動時,除了提供語言模型判斷的最佳解答以外, Bard 還會額外提供兩種不同的回答,使用者可從這三項草稿進行參考,同時使用者選擇的回答也會持續影響 Bard 的發展方向。
對話式 AI 與大型語言模型仍於發展初期、許多挑戰仍待釐清與解決
雖然目前對話式 AI 與大型語言模型有著飛躍性的成長,不過紀懷新博士強調目前仍處在技術的萌芽期,除了許多牽涉到道德、隱私的挑戰以外,也有許多定義上的未解問題,也希望目前使用 Bard 的使用者能夠理解 Google 在 Bard 服務冠上「 Beta 」象徵的意義。

▲目前大型語言模型認定的五大發展限制
紀懷新博士指出,當前大型語言的限制來自五大面向,第一是容易產生幻覺的錯誤回答的精確性問題,其次是由於引述資料與學習素材產生的偏差性,以及特定資料來自同一著作人產生的人格化,還有對於特定問題不回答或提供不適合回應的偽陽/偽陰回答,以及防範部分使用者刻意挑戰模型的惡意提示攻擊。這也是基於搜尋服務的 Bard 當前所遇到的問題,故 Bard 當前的回應都會強調引述來源,使操作者能從來源進一步查證真偽。
Google 目前還無法擔保問題能瞬間迎刃而解,然而 Google 在以大膽而負責人的前提下持續進行發展, Bard 與 Google 所有的服務將以七大方針善盡責任,其一是對社會有益,免製造與加強不公平偏見,第三是建立並測試安全性,第四是對使用的人們負責,第五是納入隱私設計原則,第六是堅持科學上卓越的最高標準,最後是依循主要目的與用途、通用與獨特的是應用、規模、 Google 扮演的角色作為應用基準。
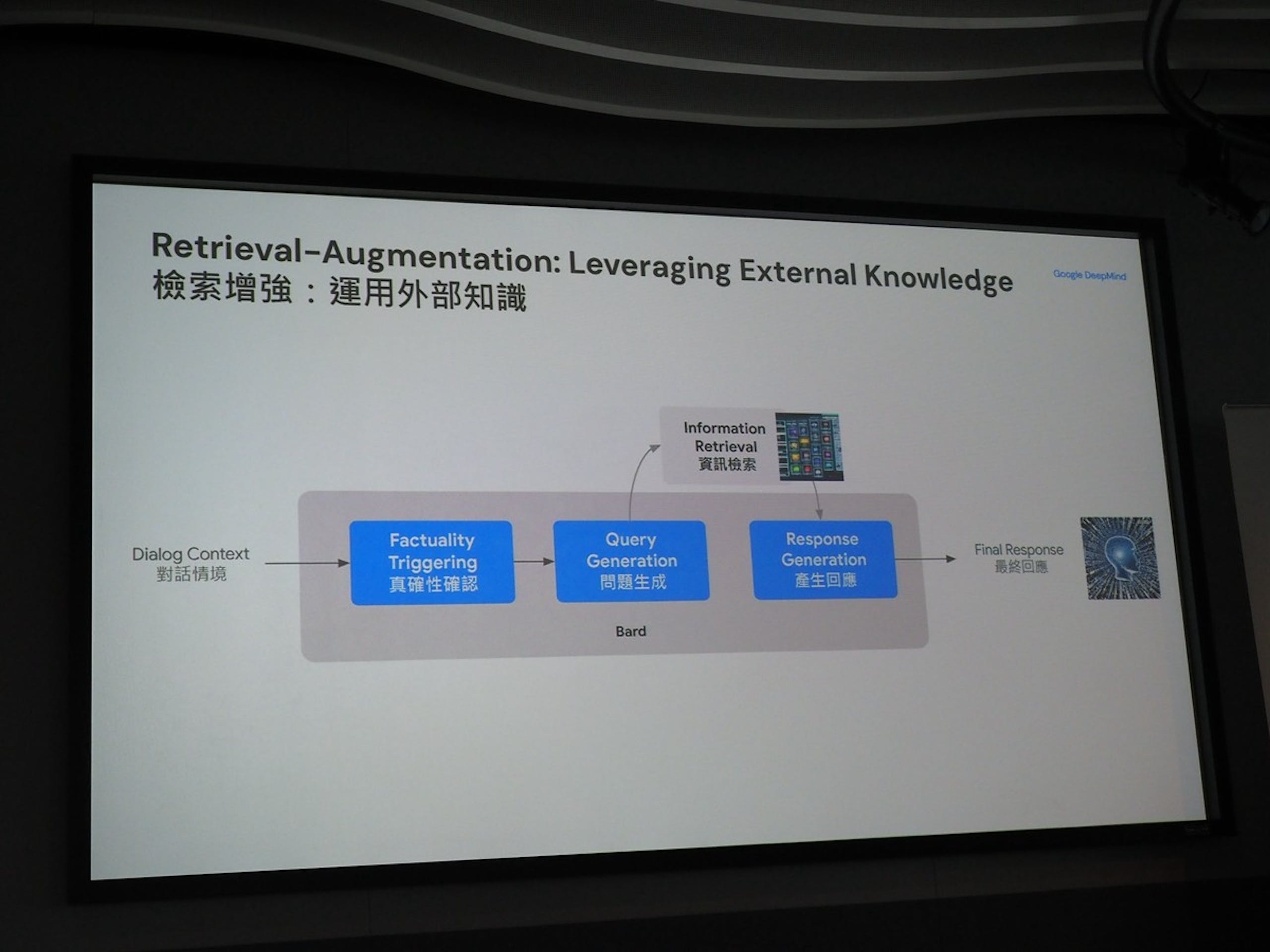
▲對於難以判斷何謂正確的內容,以提供引述資料來源的方式呈現
紀懷新博士表示,雖然從科學的角度, Bard 答案的正確性相當重要,然而在廣泛的問題當中,何謂正確答案已經屬於哲學範疇, Google 團隊只能從學術的角度以「引述」的方式提供可信度較高的回答。

▲ Google 對於 AI 的準則
此外, Google 開發團隊也意識到大型語言模型的潛力,著手開發各式的應用與不同大小的模型,使大型語言模型也能在各式裝置執行,不過這些都屬於還在研究中的項目,但最終的目標是如何在模型縮小後仍能維持與標準語言模型同等的品質。




















1 則回應