
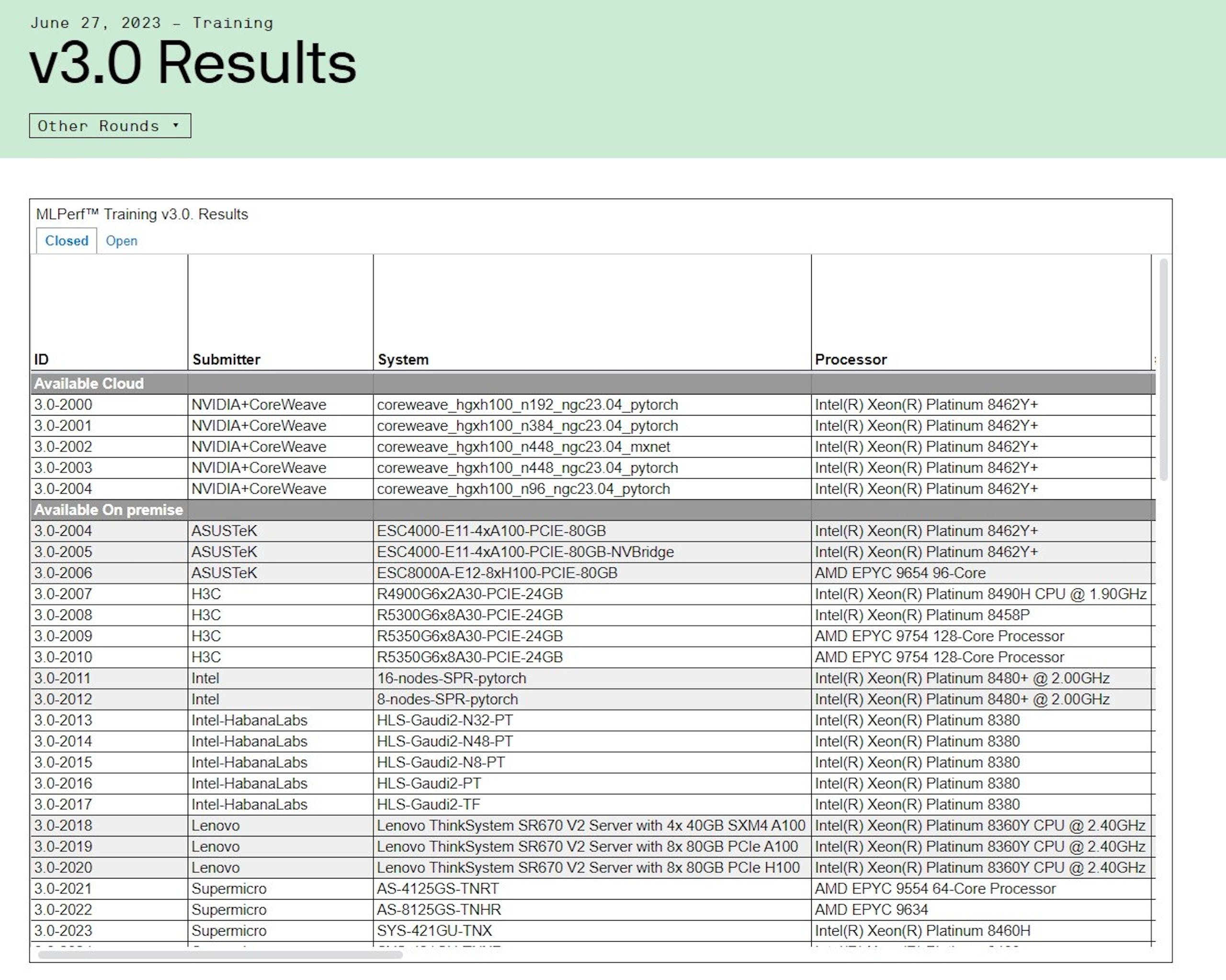
由於投入大量先前軟硬體準備以及積極開放軟體生態,現在 AI 產業產生僅有 NVIDIA 解決方案足以執行生成式 AI 與大型語言模型( LLM )訓練的迷思, Intel 在最新的 MLPerf 提交旗下包括 Habana Gaudi 2 深度學習加速器與第 4 代 Xeon Scalable 的成績,希冀以實證打破業界迷思,為希望擺脫單一生態系限制的客戶提供不同的選項。
其中最新的 MLPerf Traning 3.0 結果也證實 Habana Gaudi 2 具備完善的軟硬體技術,能在 GPT-3 獲得實證,並成為除了 NVIDIA 以外提交 GPT-3 LLM 訓練基準測試效能結果的半導體解決方案;除了具備獲得實證的效能以外, Intel 強調 Habana Gaudi 2 也式相較 NVIDIA H100 更具性價比的選擇,並預期透過後續軟體更新持續提升表現。
而首度導入 Intel AI 引擎的第 4 代 Xeon Scalable 處理器則展現深度學習訓練效能,使客戶可透過 Xeon 伺服器建構單一通用 AI 系統,處理資料預處理、模型訓練與部屬,也是當前唯一一款提交 MLPerf 成果的 CPU 產品。
Habana Gaudi 2 成除 NVIDIA 外唯一遞交 MLPerf GPT-3 LLM 訓練成果解決方案
▲ Habana Gaudi 2 是除 NVIDIA 外上繳 GPT-3 LLM 訓練成績的晶片方案
Intel Habana Gaudi 2 在 MLPerf 達成多項里程碑,其中在具備 1,750 億個參數的 GPT-3 模型訓練展現一定的效能與高效擴展性,並且是使用 PyTorch 與流行的 DeepSpeed 最佳化函式庫而非客製化軟體; Intel 藉由 384 個加速器,實現 311 分鐘完成訓練的佳績(註:目前記錄由 CoreWeave 以 3,584 個 NVIDIA H100 於 11 分鐘內完成);此外也展現在 GPT-3 由 256 個加速器增加至 384 個加速器的 95% 近線性效能增長。
除了 GPT-3 以外, Habana 也在包括 ResNet-50 的 8 個加速器、 Unet3D 8 個加速器、自然語言處理的 BERT 的 8 個與 64 個加速器取得優異的訓練成果。此外,相較 Intel 於 2023 年 11 月提交的測試結果,在 BERT 與 ResNet 模型的效能分別有 10% 與 4% 提升,顯見 Intel 的 Gaudi 2 軟體持續改善帶來效能提升。另外 Intel 指出此次於 MLPerf 3.0 的測試結果是使用 BF16 資料類型,預計 2023 年第三季提供 FP8 軟體支援與新功能,進一步提升 Gaudi 2 效能。
降低企業初期部屬 AI 負擔的第 4 代 Xeon Scalable 處理器

▲透過整合 Intel AI ,企業能使用純 CPU 系統部屬基礎的 AI
雖然當前異構加速運算是目前 AI 與深度學習的主流,不過對還在評估當中或是認為專用 AI 系統成本較高與擔心複雜度的業者, Intel 藉由在第四代 Xeon Scalable 導入 Intel AI 架構,使純 CPU 運算系統也能執行一定的 AI 訓練負載;此外對自 Intel 先前發表的結果,借助 Intel AI 軟體與標準業界開放原始碼,能使預訓練好的模型透過簡單的數分鐘微調使用企業的小型資料庫。
Intel 也指出多項第四代 Xeon Scalable 在 MLPerf 創下的紀錄,於封閉分區方面,第四代 Xeon 可在 50 分鐘內與 90 分鐘內完成 BERT 與 ResNet-50 模型;對開放分區的 BERT 則可在擴展到 16 個節點於 31 分鐘完成模型訓練;對較大的 RetinaNet 模型,透過 16 節點的 Xeon Scalable 可於 232 分鐘完成,這也表示客戶可靈活應用伺服器的零碎時間進行模型訓練。
然而 NVIDIA H100 在大型企業仍相當受重視其來有因,雖然 NVIDIA H100 價格更為高昂,但卻也是目前唯一能完整執行 MLPerf Traning 3.0 的 8 個項目的解決方案,除此之外結合 NVIDIA 的高速網路互連解決方案等,能進一步擴大大量節點的效能增長,諸如此次創下 GPT-3 訓練紀錄的系統即連接超過 3,000 個 GPU ,更不用說 NVIDIA 在軟體不僅耕耘時間更長,採取開放態度也進一步使生態鏈有更高的支援。



















