
NVIDIA 在加拿大舉行的 SIGGRAPH 率先發表基於新一代架構 Turing / 圖靈的 Quadro RTX 繪圖卡產品線,同時也似乎可視為 NVIDIA 將可能透過 Turing 架構作為新一代 GeForce 顯示卡的基礎架構,但可能會有人很納悶, Volta 架構雖有 Tesla V100 、 Titan V 與 Quadro GV100 三種版本,但基本上都是相同的核心,讓人不禁懷疑 NVIDIA 怎麼定位 Volta 架構與 Turing 的關係,以下以筆者手邊整理的簡單資訊探討 Volta 與 Turing 的產品定位。
Turing 與 Volta 具備相同的 Cuda Core 對 Tensor Core 比例
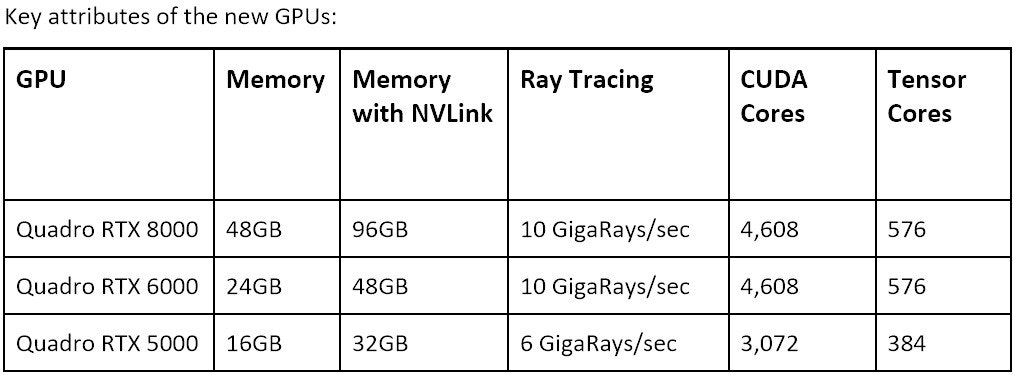
Volta 與 Turing 的 CUDA Core : Tensor Core 都是 8:1
先從基本架構方面比較,會發現 Volta 與 Turing 有些許相似之處,甚至可推測 Turing 是從 Volta 架構針對繪圖、影音娛樂調整而來的架構;從 CUDA Core 與 Tensor Core 的比例方面, Volta 架構的 Qualdro GV100 具備 5,120 個 CUDA Core ,搭配 640 個 Tensor Core ,而 Turing 的高階版 Quadro RTX 8000 則具備 4,608 個 CUDA Core ,搭配 576 個 Tensor Core ,兩個架構在 CUDA 與 Tensor Core 的比例都是 8:1 ,原本在介紹 Volta 時,也提及其 Tensor Core 是將架構分散在 CUDA Core 當中,若比例相同, Volta 與 Turing 兩項架構多少會有些許淵源。
Volta 產品聚焦超級運算與 AI 等高階應用, Turing 則鎖定主流繪圖與影像應用產品

SXM 版 Volta 可達 300GBps 的 NVLink 頻寬
然而 Turing 與 Volta 架構所側重的應用或許從額外的部分可看出來差異,首先 Volta 架構一開始就是針對能夠搭配 NVLink 的多卡串接應用與大規模記憶體共享而來,同時目標客群亦是超級電腦、人工智慧演算中心等高階應用,故在當時不惜使用單位容量成本較高的 HBM2 記憶體,不過發表 Volta 之初,黃仁勳亦提級 Volta 亦可作為專業繪圖應用,故在產品線仍針對專業繪圖領域推出了 Quadro GV100 ,並配有 32GB 的 HBM2 記憶體(頻寬為 900GBps ),且即便是 PCIe 版的 Quadro QV100 ,雙卡連接用的 NVLink 頻寬亦有 200GBps ,而原生 NVLink 介面的 SXM 版本則為 300GBps 。

Quadro RTX 僅允許雙卡 NVLink 、頻寬降為 100GBps
至於 Turing 則再度回歸到 GPU 主力的影像與娛樂應用,在加入 Tensor Core 的同時,亦針對更複雜的即時光線追蹤,導入全新的 RT Core 硬體光線追蹤加速器,使其針對光線追蹤以硬體的方式得到更高的效率,再搭配 Tensor Core 與深度學習的預推測方式,透過融合架構以更少的 GPU 數量達到即時的光線追蹤性能,同時介面設計除目前僅公布 PCIe 介面型態外,亦僅可透過 NVLink 額外再擴充一張 Turing GPU ,且頻寬也砍半到 100GBps ,然而記憶體則使用新一代的 GDDR6 RAM ,預估性能表現將相當逼近 HBM2 。
Turing 搭配 GDDR6 帶來高容量優勢

Quadro RTX 8000 達單卡 48GB 、雙卡 96GB 的高記憶體容量
雖然此次發表的 Quadro RTX 8000 售價高達 10,000 美金,甚至比 Quadro GV100 的 8,999 美金更高,但關鍵在於 Quadro RTX 8000 具備達 48GB 的記憶體,而在 NVLink 連接雙卡後更可達 96GB ,遠本 Quadro GV100 的 32GB 更具優勢,這對於專業影像創作、 3D 繪圖相當重要,尤其是為了處理高解析度影片、複雜的 3D 場景、材質等,記憶體當然也是多多益善,等同兩張 Quadro RTX 8000 就擁有大於三張 Quadro GV100 的記憶體,只是就單純運算性能,當然 Volta 仍是有所優勢的,但這是以傳統運算的部分來看。
Turing 首度將即時光線追蹤變成更貼近現實...好吧,對消費者可能還是沒那麼現實

Turing 藉由混合 CUDA 、 Tensor 與 RT 三種核心可實現單卡即時光線追蹤
雖然 Turing 帳面規格是比 Volta 差了一些沒錯,不過若回歸影像運算、尤其是 3D 場景相關,那 Turing 或許比起 Volta 在特定領域更為強勢,以稍早黃仁勳開場介紹 Turing 時,以在 GDC 大會展示過的星際大戰即時光線追蹤動畫為例,當時需要動用基於 4 張 Tesla V100 的 DGX Station ,不過現在卻僅需要單張 Quadro RTX 8000 ,關鍵的原因在於除了 AI 的預測性功能挹注外,光線追蹤的運算亦分散給專屬的 RT Core 負責,而 RTX 8000 的 RT Core 每秒可處理達 10 Giga Ray 的數量,亦省下大量的運算力。
對於希望能夠藉由導入即時光線追蹤的影像工作室,原本需要購買昂貴的 DGX Station ,但現在僅需要購買 Turing 架構的 Quadro RTX 繪圖卡,自然在成本也省下許多,同時若想要達到更進階的光線追蹤性能,甚至可購買兩張 Quadro RTX 進行 NVLink 進一步提升運算性能與記憶體總量。
此時亦可看出 NVIDIA 在 Quadro RTX 6000 與 Quadro RTX 8000 的產品定位差異,雖在運算能力方面兩者核心架構相同,僅在記憶體差了一倍,然而價差逼近 4 成,若並未用到大量材質填充,但需要更高性能的即時光線追蹤,雖然兩張 RTX 6000 僅等同單張 RTX 8000 的記憶體,不過基本性能則可藉由兩張 Quadro RTX 6000 達成超越單張 RTX 8000 的性能。
官方似乎定調 Turing 是 Pascal 後繼,那 Volta 是否會有後繼?

由於超級運算與 AI 屬於高附加價值市場, Volta 會有後繼架構並不意外,但應該不會加入 RT Core
在 AMD 當前的狀況,已經將 GPU 產品分為主流(當前的 Polaris )與旗艦(當前的 Vega )兩個不同的系列,然而就 NVIDIA 在 Turing 發表會的比較方面,幾乎都將 Turing 直接與 Pascal 對比,加上初期就公布兩種不同規格的核心( Quadro RTX 8000 與 Quadro RTX 6000 視為相同核心,而 Quadro RTX 5000 則是另一顆核心),亦可視為未來還可能持續擴大產品線。
而 Volta 架構的定位是否只是曇花一現?筆者認為在當前 NVIDIA 持續在超級運算與 AI 運算取得市場優勢的情況下,針對這樣的高附加價值市場, NVIDIA 持續投入的機率並不低,但也同時由於此項架構在成本方面較高(包括更複雜的電晶體數量、 HBM 記憶體等), NVIDIA 持續在超高階專業產品提供單一個架構名稱並不讓人意外,甚至可推測此架構由於主要定位在運算與 AI 應用,即便在 Turing 導入 RT Core 後,作為 Volta 後繼的架構也將維持在 CUDA Core 與 Tensor Core 兩種架構搭配 HBM 記憶體,不會導入與運算以及 AI 較無關的 RT Core 。



















